
CubeFS 如何在 OPPO 混合云平台中加速 AI 训练3倍
挑战
2021年,Oppo基于分布式文件系统CubeFS构建了一个大规模机器学习平台的一站式服务。2022年,为了优化成本,他们开始在机器学习平台上构建了一个混合GPU云。尽管大多数GPU计算能力仍留在Oppo的私有云中,但当其资源不足时,任务会被调度到公共GPU云进行训练。这种混合GPU云架构在CubeFS存储方面提出了几个挑战,包括存储性能、弹性和容量降低、安全问题和高成本。
解决方案
为了解决这些挑战,Oppo转向AI训练——这是一种重复、多个epoch读取数据集的过程。启用CubeFS客户端的缓存功能,将CubeFS上的训练数据缓存到GPU计算节点侧。这降低了CubeFS的元数据延迟至微秒级别,数据延迟降至百微秒级别,加速了AI训练。
效果
这种方法帮助机器学习平台实现了基于混合云GPU资源的统一存储。这不仅为业务用户提供了透明度和一致的性能,而且用户也不需要担心分开的数据集副本。
此外,启用缓存加速,利用RESNET18[1]模型(人工智能领域中的经典和通用算法模型)可将性能提高多达360%。同时,使用AlexNet[2]模型性能可提高多达130%。
使用的项目
- CubeFS[3]
- Kubernetes[4]
数字数据
- 缓存加速性能提高了360%
- 将10亿个训练模型存储在机器学习平台中
- 同步10亿个文件只需2分钟
Oppo[5]是中国最大的智能手机制造商,全球智能手机制造商市场份额排名第五,产品在超过20万个零售店销售。
在2021年,AI先驱Oppo构建了一个大规模、端到端的机器学习平台,利用CubeFS支持100多个Oppo业务的AI训练——每天运行数万个训练任务,涵盖语音助手、商业广告、OPPO游戏、ctag多模式、NLP等业务领域。
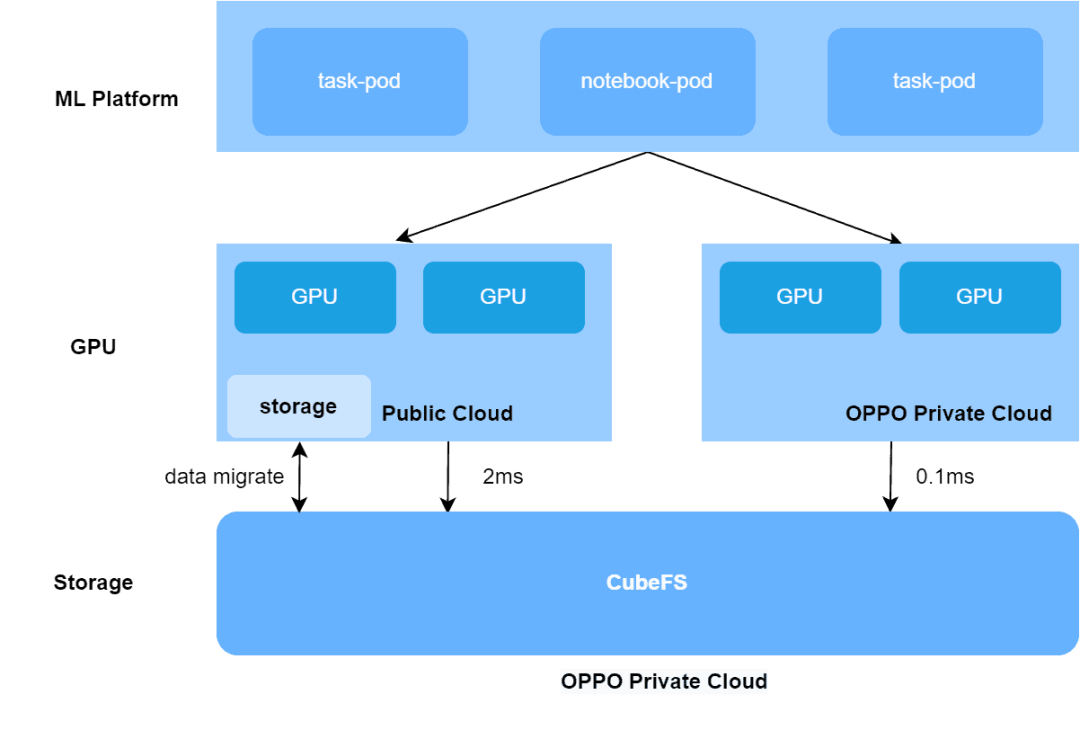
然而,由于公共云到私有云的网络延迟(2ms),公共GPU云主机访问远程CubeFS的存储性能在元数据操作、数据IO、延迟敏感的小文件训练数据集和以lmdb格式存储的大文件训练数据集方面急剧下降。
通过比较公共GPU云和私有GPU云的训练任务,Oppo发现单个GPU卡每个epoch处理的图像样本差异为2-4倍。同时,IO瓶颈导致GPU卡的利用率低,浪费了任务训练时间和GPU资源。
为什么选择CubeFS?
CubeFS是由Cloud Native Computing Foundation[6]作为孵化项目托管的云原生存储平台。它通常用作在线应用、数据库、数据处理服务和由Kubernetes[8]编排的机器学习作业的存储基础设施。其优点之一是将存储与计算分离,可以根据工作负载独立地进行扩展或缩减,提供了完全的灵活性,以匹配任何给定时间实际所需的存储和计算能力资源。
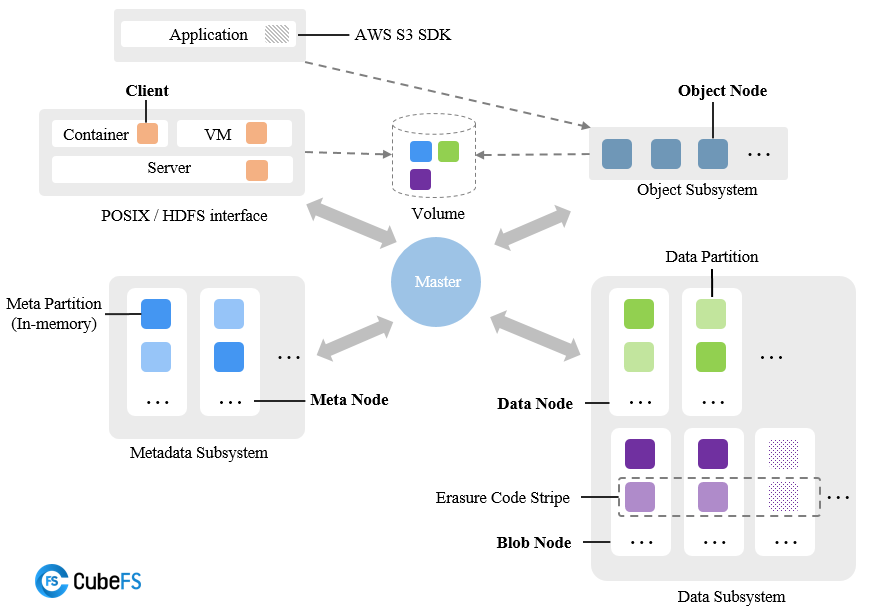
CubeFS由元数据子系统、数据子系统和资源管理器组成,可以通过不同的客户端(作为一组应用程序进程)通过称为卷的不同文件系统实例访问。CubeFS的特点包括:
- 多种访问协议,允许用户通过多种协议访问同一文件,如POSIX/HDFS/S3。
- 具有强一致性的高度可扩展的元数据服务。
- 通过优化大型/小型文件和顺序/随机写入实现优异的存储性能。
- 支持多租户,具有更好的资源利用率和租户隔离。
- 通过多级缓存实现混合云I/O加速。
- 灵活的存储策略、高性能的复制和低成本的纠删码。
弹性容量和安全性
为解决Oppo的混合云存储性能问题,AI训练任务在初始阶段被调度到公共云。然而,这要求用户将Oppo私有云中的CubeFS数据迁移到公共云存储中,这意味着数据集面临安全合规问题,导致用户体验差,解决安全问题的成本高,因为机器学习平台无法灵活地调度GPU计算能力。
为了解决这些问题,Oppo找到了许多创新的数据缓存解决方案:
数据缓存
数据加速的目的是将文件的数据扩展缓存到本地磁盘。由于磁盘资源限制,多个训练任务需要共享缓存磁盘空间。数据缓存充当单独的数据读写服务,管理缓存数据,提供接口:读操作、写操作、删除操作和缓存数据的GC。
缓存布局:CubeFS中的文件由数据扩展组成。为了方便管理缓存文件数据,缓存一个完整的扩展,一个扩展碎片键命名约定:volume name_inodeId_extentId_fileoffset在文件中唯一标识一个扩展。扩展在缓存目录中的位置由哈希规则计算得出。
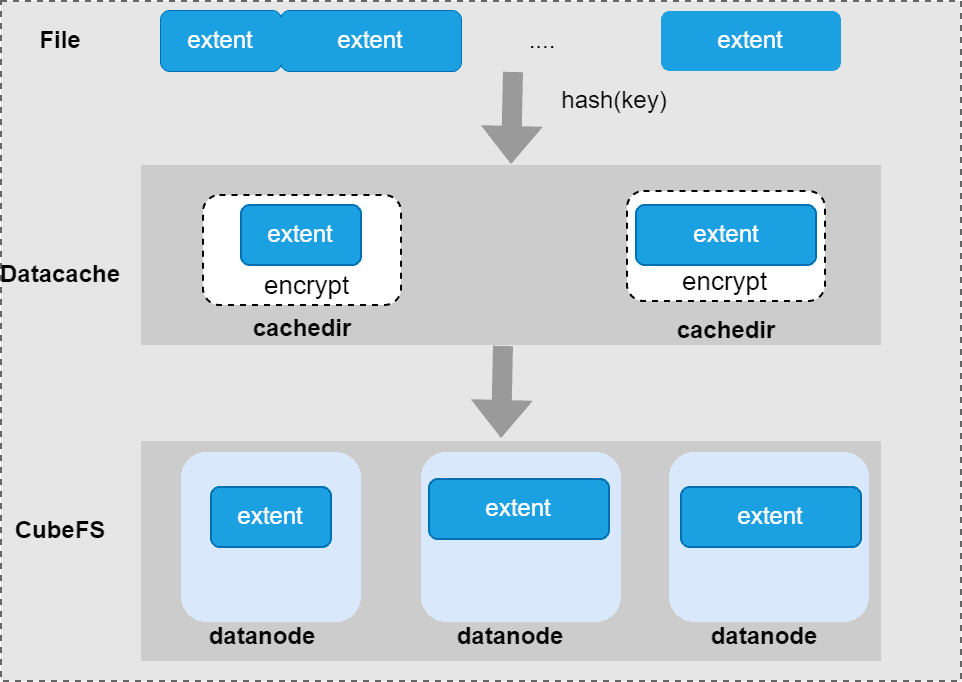
缓存一致性
尽管AI训练是一个无写入/多读取的过程,但仍需要确保某些修改后的文件的缓存一致性:
- 强一致性: 客户端基于文件扩展名进行配置,过滤不需要访问缓存的文件类型,直接从CubeFS存储后端读取数据和元数据,例如应用程序配置文件和元数据。
- 最终一致性: 确保缓存文件数据的一致性,确保训练任务的正确性。CubeFS客户端的缓存数据和CubeFS存储后端的数据是相互独立的,必须通过有效的缓存更新机制来保持一致性。CubeFS客户端使用依赖关系管理机制来跟踪缓存文件之间的依赖关系,以确保缓存数据仅在数据更新时进行重建。
未来规划
CubeFS目前作为Oppo机器学习平台的存储引擎,支持数十亿的业务规模和数百亿的训练模型,提供服务可用性、性能和可扩展性。
由于CubeFS基于客户端缓存解决方案来拉取远程数据到计算节点进行存储加速,为了进一步扩展当前用例,训练数据集可以存储在更低成本的HDD CubeFS集群中。在进行AI训练时,启用客户端缓存加速可以更好地平衡存储成本和性能。
未来,Oppo计划进一步利用CubeFS来实现GPU计算引擎在多私有云场景中的弹性调度能力。
参考文档
[1] RESNET18: https://pytorch.org/vision/main/models/generated/torchvision.models.resnet18.html
[2] AlexNet: https://en.wikipedia.org/wiki/AlexNet
[3] CubeFS: https://www.cubefs.io/
[4] Kubernetes: https://kubernetes.io/
[5] Oppo: https://www.oppo.com/
[6] Cloud Native Computing Foundation: https://cncf.io/
[7] incubating: https://www.cncf.io/projects/
[8] Kubernetes: https://www.cncf.io/projects/kubernetes/