
How CubeFS Accelerates AI training 3x in OPPO Hybrid Cloud platform
Challenge
In 2021, Oppo built a one-stop service for a large-scale machine learning platform based on the distributed file system CubeFS. In 2022, to optimize costs, they began to build a hybrid GPU cloud on machine learning platforms. While the majority of the GPUs computing power remained in Oppo’s private cloud, when its resources were insufficient tasks would be scheduled to the public GPU cloud for training. This hybrid GPU-cloud architecture presented several challenges in CubeFS storage, including storage performance, lowered elasticity and capacity, security issues, and high costs.
Solution
To tackle these challenges, Oppo turned to AI training – a process of repeated, multiple epoch reads of a dataset. Enabling the caching function of CubeFS’s client, the training data on CubeFS is cached to the GPU computing node side. This reduces CubeFS’ metadata latency to the microsecond, and data latency down to the hundred-microsecond level – accelerating AI training.
Impact
This approach has helped the machine learning platform realize unified storage based on hybrid cloud GPU resources. Not only does this provide transparency for business users, with consistent performance, users also don’t need to worry about separate dataset copies.
Plus, with cache acceleration enabled, leveraging the RESNET18[1] model (a classic and universal algorithm model in the field of artificial intelligence) improves performance by up to 360%. Meanwhile, using the AlexNet[2] model improves performance by up to 130%.
PROJECTS USED
- CubeFS[3]
- Kubernetes[4]
BY THE NUMBERS
- 360% IMPROVEMENT On performance with cache acceleration
- 2 MINUTES To sync 10 million files
- 100 BILLION TRAINING MODELS Stored in machine learning platform
Oppo[5] is China’s largest smartphone manufacturer, holding the fifth largest market share of smartphone manufacturers globally, with devices sold in more than 200,000 retail outlets.
In 2021, AI pioneers Oppo built a large-scale, end-to-end machine learning platform, leveraging CubeFS, to support AI training for more than 100 Oppo businesses – running tens of thousands of training tasks every day for business fields including voice assistant, commercial advertisement, OPPO game, ctag multi-mode, NLP and more.
However, due to network latency (2ms) from the public cloud to the private cloud, the storage performance of the public GPU cloud host accessing remote CubeFS decreased sharply for metadata operations, data IO, latency-sensitive small file training datasets and large file training datasets in lmdb format.
By comparing the training tasks of the public GPU cloud and private GPU cloud, Oppo found that the image samples processed by a single GPU card per epoch were 2-4 times different. At the same time, the IO bottleneck led to low utilization of GPU cards, wasting task training time and GPU resources.
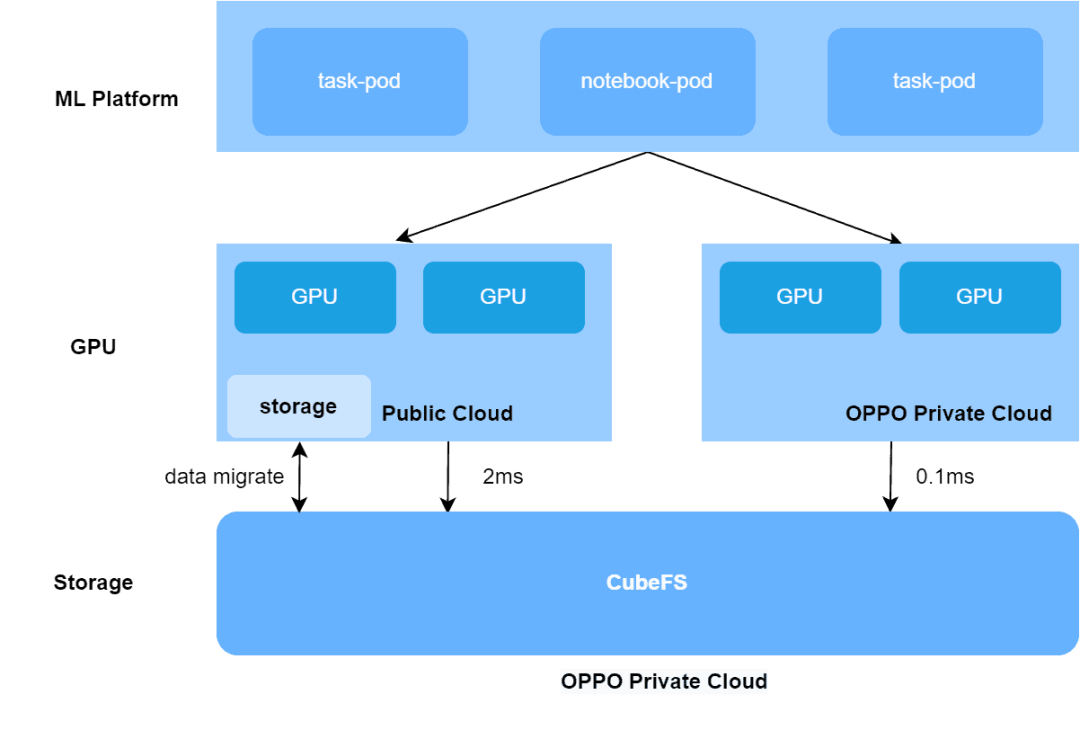
Why CubeFS?
CubeFS is a cloud-native storage platform hosted by the Cloud Native Computing Foundation[6] as an incubating[7] project. It is commonly used as the storage infrastructure for online applications, database, data processing services, and machine learning jobs orchestrated by Kubernetes[8]. One of the advantages is that it separates storage from computing, which can scale up or down based on the workload independently, providing total flexibility in matching resources to the actual storage and compute capacity required at any given time.
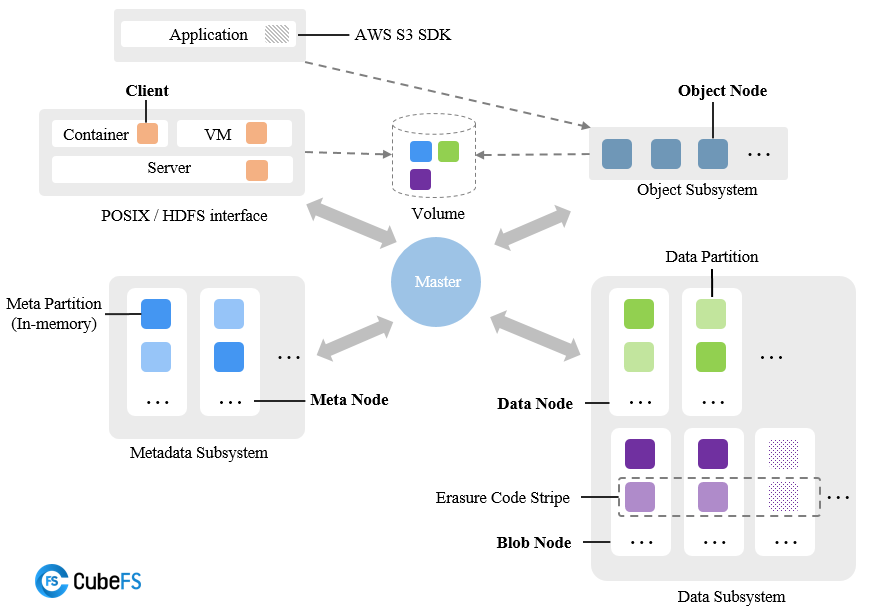
CubeFS consists of a metadata subsystem, data subsystem, and resource manager – which can be accessed by different clients (as a set of application processes) hosted on the containers through different file system instances called volumes. CubeFS features:
- Multiple access protocols, allowing users to access the same file over multiple protocols, such as POSIX/HDFS/S3.
- Highly scalable metadata service with strong consistency.
- Excellent storage performance via optimizing large/small files and sequential/random writes.
- Multi-tenancy support with better resource utilization and tenant isolation.
- Hybrid cloud I/O acceleration through multi-level caching.
- Flexible storage policies, high-performance replication, and low-cost erasure coding.
Elastic capacity and security
To solve Oppo’s hybrid cloud storage performance problem, AI training tasks are scheduled to the public cloud in the initial stages. However, this requires users to migrate CubeFS data in the Oppo private cloud to public cloud storage, meaning datasets face issues with security compliance, leading to a poor user experience and high costs to address security issues individually, because machine learning platforms cannot schedule GPU computing power with flexibility.
To tackle these issues, Oppo found a number of innovative data-caching solutions:
Data cache
The purpose of data acceleration is to cache the data extent of a file to the local disk. Due to disk resource limitations, multiple training tasks need to share cache disk space. The data cache acts as a separate data read and write service that manages cached data, which provide interfaces: read operation, write operation, delete operation, and GC of cached data.
cache layout: A file in CubeFS consists of data extents. To facilitate the management of cached file data, a full extent is cached and an extent shard key naming convention: volume name_inodeId_extentId_fileoffset in the file uniquely identifies an extent. The location of the extent on the cache directory is computed by hash rules.
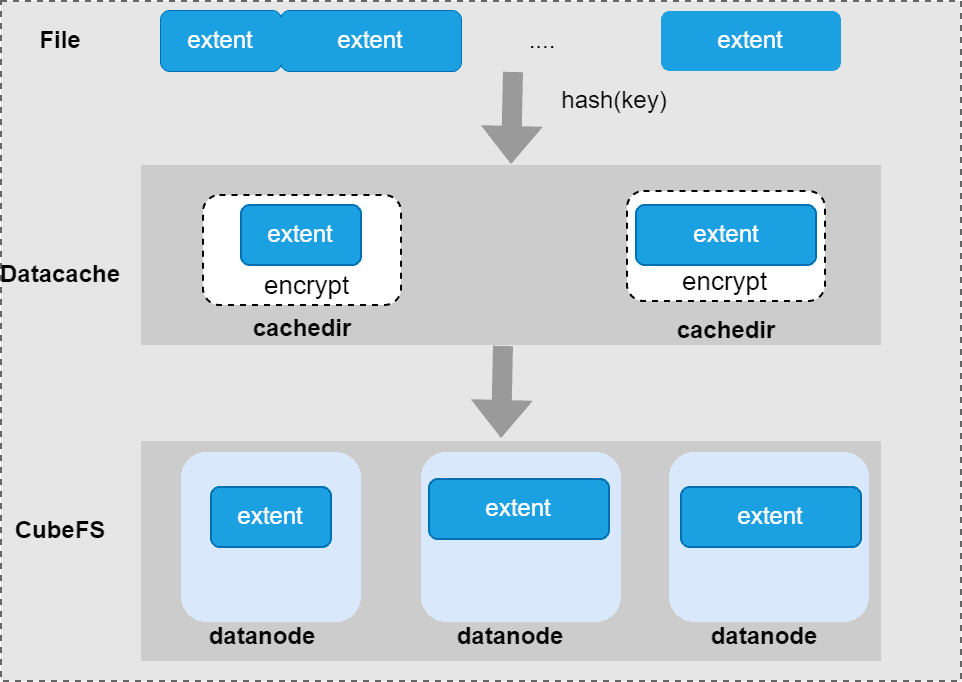
Cache consistent
Although the AI training is a write-less/read-more process, it is still necessary to ensure cache consistency for some modified files:
- Strong consistency: The client is configured based on file extensions, filtering out file types that do not require access to the cache, and reading data and metadata directly from the CubeFS storage backend, such as for application program files and configuration files.
- Final consistency: CubeFS client starts the meta sync task, scans the metadata of all files in the cache, queries all updated cache data during the scan cycle, updates the metadata cache if the file is changed, and drops the cache data in the cache directory. With 10 million files, it takes only two minutes to sync.
What’s next for Oppo?
Today, CubeFS is used as the storage engine of Oppo’s machine learning platform, which supports the scale of tens of billions of business, and hundreds of billions of training models in terms of service availability, performance and scalability.
Because CubeFS is based on a client-side, caching solution to pull remote data to computing nodes for storage acceleration, to further expand the current use case, training datasets can be stored in the lower-cost HDD CubeFS cluster. When performing AI training, the client-side cache acceleration is enabled, which can better balance storage cost and performance.
In the future, Oppo plans to further utilize CubeFS to realize the elastic scheduling capability of the GPUs computing engine in the multi-private cloud scenario.
References
[1] RESNET18: https://pytorch.org/vision/main/models/generated/torchvision.models.resnet18.html
[2] AlexNet: https://en.wikipedia.org/wiki/AlexNet
[3] CubeFS: https://www.cubefs.io/
[4] Kubernetes: https://kubernetes.io/
[5] Oppo: https://www.oppo.com/
[6] Cloud Native Computing Foundation: https://cncf.io/
[7] incubating: https://www.cncf.io/projects/
[8] Kubernetes: https://www.cncf.io/projects/kubernetes/