
Co-creating the Future with CubeFS: BIGO's Practice and Reflection
Background
platform grows, more requirements have been proposed for the underlying file system, such as multi-tenancy, high concurrency, multi-datacenter high availability, high performance, cloud-native, and other features.
Technology Selection
After comparing and evaluating from multiple angles, we found that CubeFS has many features that are suitable for our machine learning platform's use cases:
- Tenant Isolation: CubeFS can create different volumes for different business lines to achieve tenant isolation.
- High Concurrency: When our models are trained, tens of thousands of clients mount the same instance for reading and writing, which requires high concurrency access. CubeFS distributes requests to multiple metadata nodes through sharding, making it suitable for high concurrency access scenarios.
- Massive Small Files: We mainly store small files, and CubeFS optimizes small file storage by aggregating small file contents into one file. Meanwhile, CubeFS has the metadata feature of dynamic expansion, so there won't be memory bottlenecks in a single metadata node.
From Testing to Production
We began systematic testing of CubeFS in November 2022, and based on the test results, CubeFS can meet our usage requirements well in terms of both functionality and performance. Therefore, we decided to use CubeFS to build the file storage service in our production environment and began long-term steady testing.
During this period, we also fixed some bugs and optimized functions to improve system stability and operational efficiency. During the testing process, we did not encounter serious problems, especially application freezes caused by server or client exceptions. The testing results were recognized by users.
Finally, in March 2023, we began to migrate tasks and data in the production environment to the CubeFS cluster. Currently, our machine learning platform realizes shared access by mounting CubeFS in a container and reads and writes configuration files and application logs during model training.
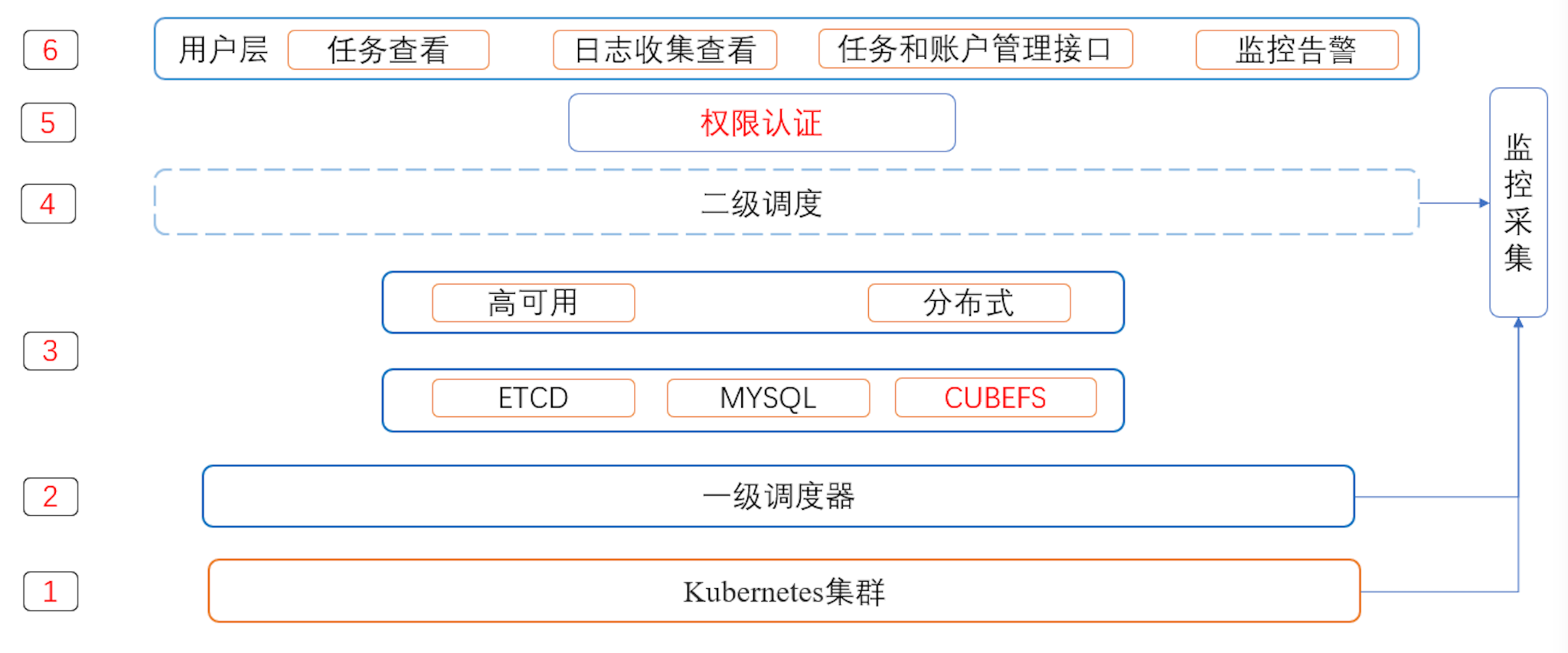
Practice in BIGO
Here are some of the work we did in practice with CubeFS.
Stability Optimization
During testing, we fixed multiple issues to improve system stability, added some commands to improve operational efficiency, and added multiple monitoring tools to help with issue diagnosis. The relevant PRs are listed below:
[Bug]: datanode shutdown may cause client failed #issue-1794
[Bug]: fix some bug to improve cluster stability #issue-1786
[Feature]: add more info to cli/fsck cmd #issue-1793
[Feature]: add some metrics #issue-1785
Addition of Audit Log Functionality
In the production environment, we needed audit log functionality to check whether client operations were compliant and to assist in analyzing client operation logic. After communicating with the CubeFS community, we confirmed that the community would include audit log functionality in the client and release it in version 3.2.1. Therefore, we decided to develop audit log functionality in our internal version first.
Since client operation commands in the FUSE layer are split into multiple operations and sent to the MetaNode, the first information that needs to be collected for audit logging on the server side is the full path of the request. After communicating with the CubeFS community, we learned that we could use the nodeCache structure in the FUSE client to reverse-engineer the parent directory node until we reached the root directory, and then assemble the full path. Another piece of information that needs to be obtained is the user information, which can be obtained by using the user.LookupId request to reverse-parse the UID information in the fuse.request and cache the user information with the UID on the client side to reduce request calls. Finally, the audit log-related information is sent to the MetaNode node, and the command information is marked to indicate which command the MetaNode-related operation came from.
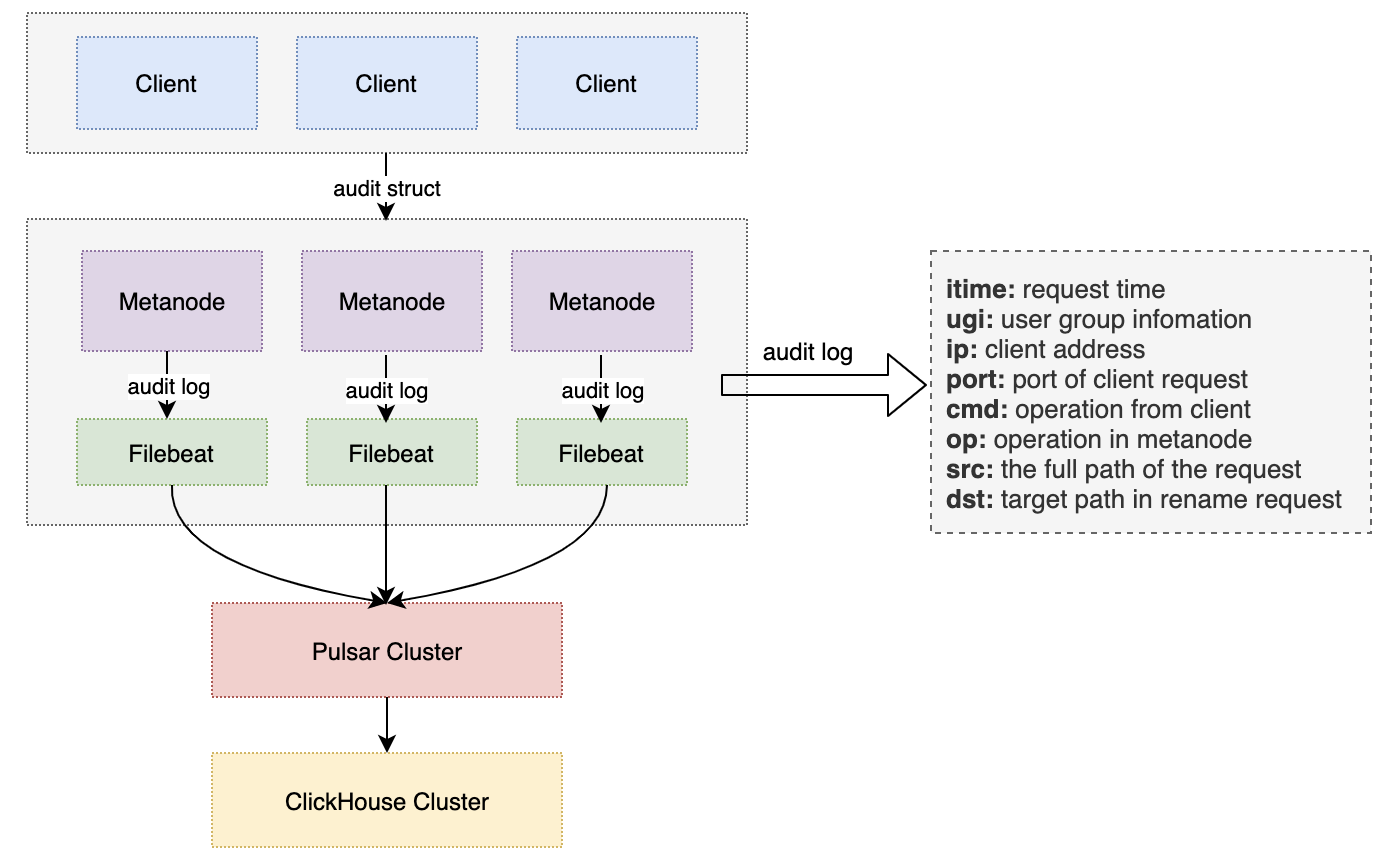
After the MetaNode writes the audit log, it can be collected by Filebeat and written to the Pulsar cluster, and finally written to ClickHouse for multidimensional queries using SQL statements.
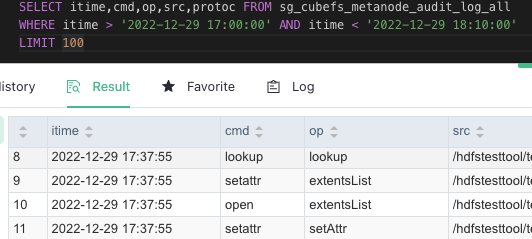
Since the community already has audit log-related functionality, we did not submit the relevant code to the community, and this feature has already been launched internally in the production environment.
Addition of Client Timeout Detection and Error Reporting Functionality
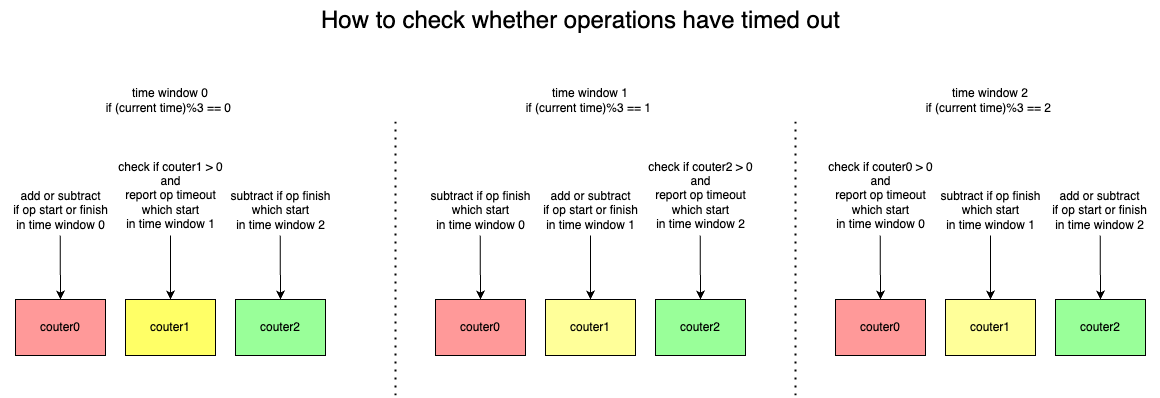
Based on our users' past experiences with other file services, they wanted us to provide a feature that can quickly detect request timeouts and return errors when server exceptions cause requests to be blocked. In order to quickly and accurately identify whether a request has timed out, if we allocate one coroutine to monitor each operation on the client side, a large number of coroutines will need to be started, resulting in waste of resources. Therefore, we implemented an algorithm that uses only one coroutine to detect all operation timeouts, and can identify which process and which operation has timed out, making it easy to quickly troubleshoot the cause of the timeout.
The basic idea of the algorithm is that assuming the timeout time equals a time window size, if a client operation starts in the current time window (denoted as window a), we will increment the counter corresponding to window a (denoted as counter a). If the operation is completed within the timeout time, we will decrement counter a. Thus, when window a ends, after waiting for one more time window, the value recorded in counter a will be the number of timed-out operations. In this algorithm, we give three counters and let them work in rotation to ensure the accuracy of operation timeout statistics.
To be able to return an error to the client after a request times out, we added timeout detection at the FUSE layer. If the processing time of a request exceeds a certain threshold, the client will receive a timeout error. We control this feature to only be used for certain users through configuration. Relevant PRs:
[Enhancement] add request monitor for client #pr-1863
[Enhancemant] Support fuse request timeout, add client metrics #pr-1674
Addition of Cluster Identification Functionality
During an upgrade process of the CubeFS cluster, we mistakenly used the configuration of Cluster B to start the MetaNode of Cluster A. The MetaNode was successfully started, but it was joined to Cluster B. After discovering the issue, we quickly took the node offline from Cluster B and re-added it to Cluster A. If two MetaNodes from Cluster A were mistakenly added to Cluster B, some metapartitions in Cluster A might miss two replicas, causing serious consequences.
The main reason for this issue is that the MetaNode and DataNode did not check whether the node itself already belonged to a cluster during the startup process. Therefore, we developed cluster identification functionality, which generates a unique cluster ID through a command and persists it in the rocksdb of the Master. When the MetaNode and DataNode are started for the first time, they will retrieve the ID from the Master and persist it in the data directory. Afterward, they will check against the ID recorded by the Master during restart, ensuring that they will not be added to other clusters. At the same time, to be compatible with old clusters, we added a switch to control the cluster ID detection functionality. If an old cluster wants to upgrade this feature, it only needs to copy the generated persistent file to the data directory of the cluster node and restart the node. Relevant PR:
Feature: add ClusterUUID for mn/dn to identify a cluster upon restart #pr-1862
Addition of Automatic Data Replica Recovery Functionality
In CubeFS, DataNodes store data shards and to ensure data reliability, the shards are saved in three replicas on disks of different DataNodes. However, because disks may become damaged, reducing the number of replicas, when all three replicas are damaged, data loss may occur. Therefore, in addition to promptly detecting missing data replicas, it is also necessary to promptly add data replicas. Generally, human intervention may be delayed and there may be risks of operational errors, so we developed automatic data replica recovery functionality. When a missing data replica is detected, it will automatically be scheduled to a suitable node to add data replicas, reducing human operational costs through automated repair. Relevant PR:
[Enhancement] automatically add data replica for data partitions which lack replica #pr-1676
Addition of Automatic Data Node and Disk Decommissioning Functionality
When a DataNode process exits due to some reason, multiple datapartitions may be missing one replica and it is necessary to quickly take the node offline to reduce the risk of data loss. To reduce human operational costs, we developed automatic DataNode and disk decommissioning functionality. When the DataNode process exits, the Master will detect the abnormality through heartbeats and automatically take the node offline from the resource nodes, then gradually schedule the datapartitions of the node to be decommissioned to other nodes and control the decommissioning speed to ensure that it does not have too much impact on the cluster's performance. This functionality also includes the automatic disk decommissioning functionality, which reports disk damage to the Master, which will then automatically schedule the datapartitions on the disk to be migrated to other nodes.
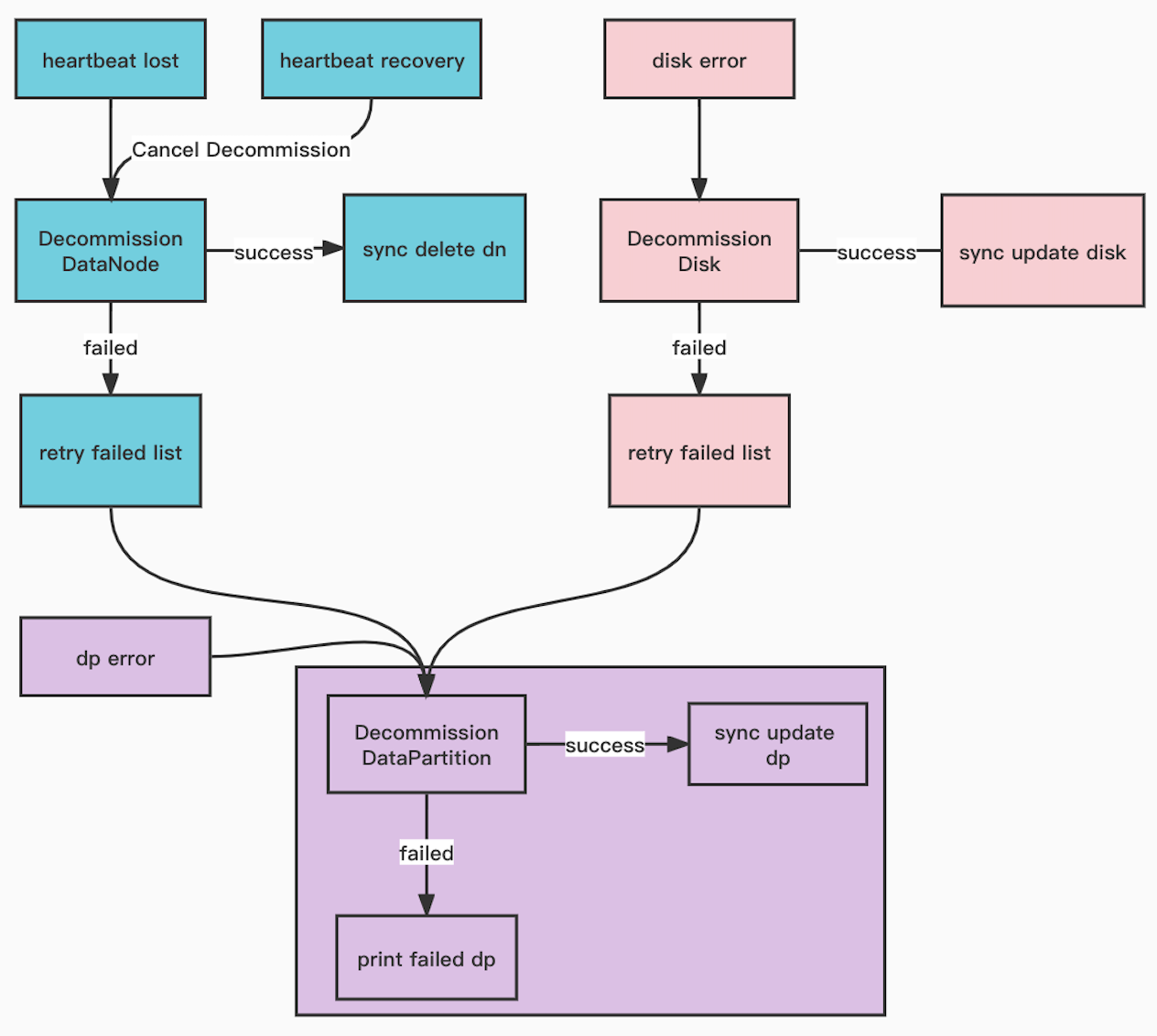
Relevant PR:
[Feature] Decommission datapartitions, disks and datanodes automatically #pr-1709
Acceleration of Metadata Node Startup
The metadata node loads all metadata into memory, and when there are a large number of files in the cluster, restarting the metadata node can take a long time, especially when upgrading the version, as all metadata nodes in the entire cluster need to be restarted, resulting in a long time. By examining the code, we found that when the MetaNode starts up, each metapartition loads metadata files in serial and there is no interdependency between each file. Therefore, we can shorten the startup time by concurrently loading multiple files, and after optimization, the MetaNode startup time can be reduced by about 50%. Subsequently, multiple coroutines can be used to load the same metadata file for further optimization. Relevant PR:
[Enhancement] speed up metanode startup #pr-1643
Addition of File Statistics Functionality
To understand the business characteristics and load of each volume and to facilitate the statistical cost of volume usage, we need to know the file usage of each volume, such as whether the volume uses large files or small files more, and the proportion of file sizes. We parse the snapshot files of each metapartition, classify volumes, control the statistical frequency and parsing rate of files, reduce the impact of this functionality on the overall cluster performance, and finally report the data to the monitoring system. This allows us to view the file distribution of each volume on the monitoring page. The figure below shows the file distribution of a certain volume.
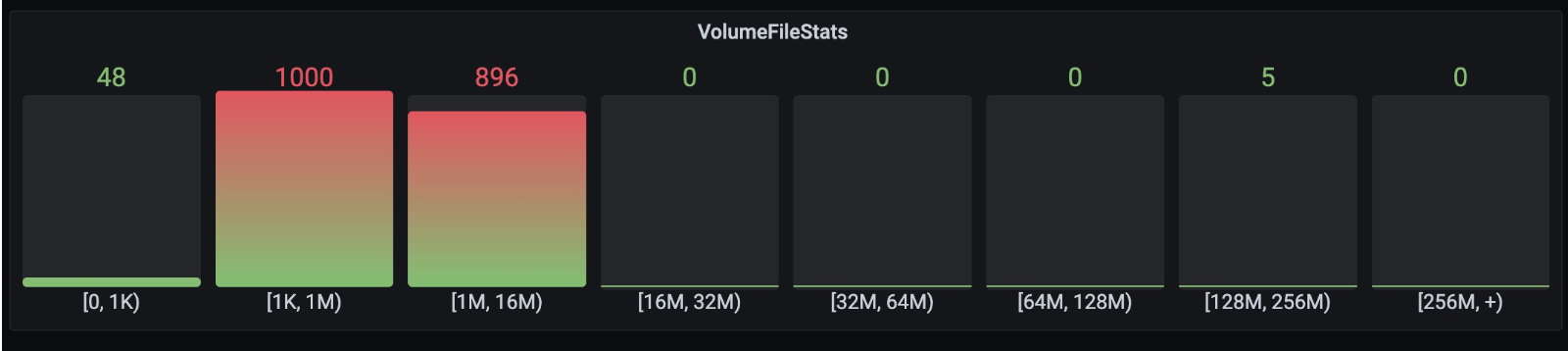
Relevant PR:
[Feature] add file statistics function #1739
Future Outlook
Currently, our production cluster has not been online for long, and our work mainly revolves around system stability and automated operations and maintenance, providing mainly file storage-related features. In the future, we will continue to work on system stability and security, guaranteeing user experience and data security, and we will expand our object storage functionality to provide object storage services for users who need them.
Conclusion and Thanks
The above are some of our work in the process of practicing CubeFS, and we will work more closely with the community in the future, trying to develop more functionality and make more contributions to the CubeFS development community. Here, we would also like to thank the CubeFS community and the OPPO team for their great support in helping us quickly familiarize ourselves with CubeFS and promptly answer our questions.